python Create videos with Python and become a vlogger Doing vlogging is time-consuming, it’s not fun, and it ruins your privacy. So make Python do everything for you.
Art Daily Sketches At the beginning of the year, I began a regular code sketching practice to stay sane while staying home. The gist of code sketching is to make generative visual artworks within a short time.
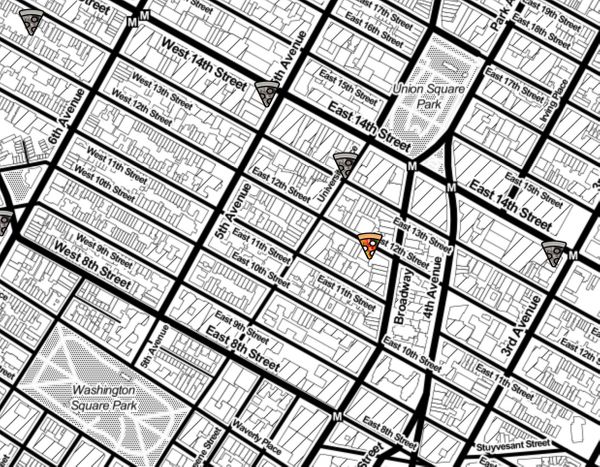
ML Find pizza with AI help There are only 124 authentic pizza places out of 1579 in New York. This is what an AI said. Combining computer vision and machine learning to ease the search for Neapolitan pizza based on photos from public crowd-sourced reviews.
ML Detect underdog stocks to buy during pandemic Everyone takes great pleasure in betting on underdogs that end up having the biggest yield, and here is the way how you can find them using Dynamic Time Warping.
ML Modernisme meets StyleGAN Train StyleGAN2 on custom dataset and generate Art Nouveau architectural elements.
ML DataSound Music is an assortment of tones of various frequencies. Volatility grips financial markets with the prices surging. So, let's make music from financial data.
ML Learning Path to TensorFlow Developer Certification I’ve passed the TensorFlow Developer Certificate exam recently and would love to share my thoughts on it and the resources used to prepare which might help you to nail it.
AWS Hosting your blog for peanuts The super fast and easy way to host your blog with AWS S3, Route 53, Cloudfront for almost nothing.
python Juiced Group in Pandas Groupby is a pretty simple concept, but in order to make the best use of it, here is one naive example.
Highlighting code in Ghost With Ghost you can easily embed code in posts. Although, with markdown language you face lack of code formatting and get code block without syntax highlighting.
Flickr integration Ghost platform supports Flickr via OEmbed integration. Simply copy the URL of the photo and paste it into editor.
Sports Fukuoka – Tokyo bike ride Completed Fukuoka to Tokyo 1300 km route by bicycle on the 30-year-old Japanese frame.
Art Trip to Morocco Highlights from my winter trip to Morocco. Tangier, Chefchaouen, Fes, Rabat, Marrakesh, and more.
Sports Mountaineering Camp, Kazakhstan Three marvellous weeks in Kazakhstan. The camp located near Tuyuk-su Glacier.
Sports Munich to Athens by bike From Munich to Athens in 15 days by bike, 10 countries, 2200 km, 22.8k elevation gain.