Finding some old files or recent work with inconsistent file names might be a challenge. I developed and applied a machine learning-based algorithm to sort all these files out automatically. It was part of internship projects which I mentored.
Designers’ Dropbox folder contains tens of thousands of files – splash screens, UI elements of our IDEs, some screenshots, booklets, icons, and photos. Some of them (thousands of files) are storing with an inconsistent path or under an inconsistent name.
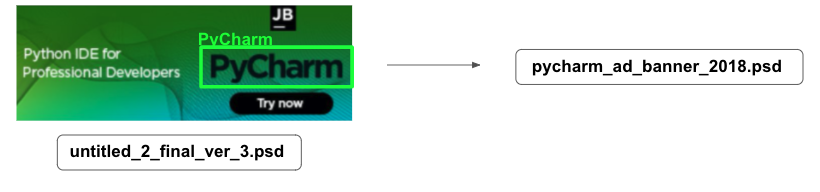
Processing pipeline
- Auto-label all the files with proper naming using Dropbox API and add them to the training dataset, add the rest to the inference list.
- Train Convolutional Neural Network (CNN) with training dataset (OCR model is pre-trained).
- Pass unlabeled files to CNN and OCR models, merge the results.
- Add corresponding Finder comment for each recognized file and create ‘metafolder’ (next slides provide further details).

Model architecture
- Classic CNN performs relatively poorly on such dataset, even with data augmentation.
- Using ResNet as a base model, we substituted its bottleneck with global maximum pooling followed by 1*1 convolution.
- Being more robust to spatial translations and transformations, average global pooling usually performs better, but in our specific case, maximum global pooling turned out to be more effective (probably due to sparsity and artificial nature of spatial data in our dataset).
Technology stack
- PyTorch
- Tesseract OCR (wrapped via tesserocr)
- Dropbox API.
Results
Every file is labeled via Finder metadata so that it could be easily found using Spotlight. MacOS stores Finder file metadata as a set of extended file attributes and indexes them along with its name and contents, so we just put a metadata label for each file.

However, it works only with files which are already synchronized on your Mac (and unfortunately, Finder metadata are not indexed by Dropbox web search), so at the same time we developed the ‘metafolder’ - a labeled catalogue of dropbox shortcuts. It allows to search for files in the web version of Dropbox.